August 22, 2017.
The first Bitcoin paper was first released in 2008. My excitement about the potential of blockchain technology has been building ever since.
Decentralized digital currency, once just a far-fetched goal, is finally making inroads into the mainstream. While that’s exciting on its own merit, I’m personally most excited about the potential for decentralized applications. Financial exchanges, prediction markets, and asset management platforms all carry enormous potential.
Written by Preethi Kasireddy - Originally published at this link.
The trustless systems supporting them are no less intriguing; identity verification systems, smart property, censorship resistant social platforms, and autonomous structures and governance models like DAOs. The most disruptive use cases probably haven’t even been dreamt up yet.
But this dream still remains a dream for the foreseeable future — while a few early enthusiasts and entrepreneurs are experimenting with building such applications, there’s still a big missing piece that prevents us from seeing these applications come to fruition: scalability. Blockchains, as it stands today, are limited in their ability to scale.
That’s not to say that this will be the case forever, but it’s definitely true today. In fact, I’d argue it’s one of the biggest technological barriers we face with blockchain technology today. It’s quickly become a very active area of research among researchers in the community and cryptocurrency in general.
Why isn’t the blockchain scalable?
Currently, all blockchain consensus protocols (eg. Bitcoin, Ethereum, Ripple, Tendermint) have a challenging limitation: every fully participating node in the network must process every transaction. Recall that blockchains have one inherent critical characteristic — “decentralization” — which means that every single node on the network processes every transaction and maintains a copy of the entire state.
While a decentralization consensus mechanism offers some critical benefits, such as fault tolerance, a strong guarantee of security, political neutrality, and authenticity, it comes at the cost of scalability. The number of transactions the blockchain can process can never exceed that of a single node that is participating in the network. In fact, the blockchain actually gets weaker as more nodes are added to its network because of the inter-node latency that logarithmically increases with every additional node.
In a traditional database system, the solution to scalability is to add more servers (i.e. compute power) to handle the added transactions. In the decentralized blockchain world where every node needs to process and validate every transaction, it would require us to add more compute to every node for the network to get faster. Having no control over every public node in the network leaves us in a pickle.
As a result, all public blockchain consensus protocols that operate in such a decentralized manner make the tradeoff between low transaction throughput and high degree of centralization. In other words, as the size of the blockchain grows, the requirements for storage, bandwidth, and compute power required by fully participating in the network increases. At some point, it becomes unwieldy enough that it’s only feasible for a few nodes to process a block — leading to the risk of centralization.
In order to scale, the blockchain protocol must figure out a mechanism to limit the number of participating nodes needed to validate each transaction, without losing the network’s trust that each transaction is valid. It might sound simple in words, but is technologically very difficult. Why?
- Since every node is not allowed to validate every transaction, we somehow need nodes to have a statistical and economic means to ensure that other blocks (which they are not personally validating) are secure.
- There must be some way to guarantee data availability. In other words, even if a block looks valid from the perspective of a node not directly validating that block, making the data for that block unavailable leads to a situation where no other validator in the network can validate transactions or produce new blocks, and we end up stuck in the current state. (There are several reasons a node might go offline, including malicious attack and power loss.)
- Transactions need to be processed by different nodes in parallel in order to achieve scalability. However, transitioning state on the blockchain also has several non-parallelizable (serial) parts, so we’re faced with some restrictions on how we can transition state on the blockchain while balancing both parallelizability and utility.
Gimme the numbers
So what do the scalability numbers actually look like? Let’s take a look.
An Ethereum node’s maximum theoretical transaction processing capacity is over 1,000 transactions per second [1]. Unfortunately, this is not the actual throughput due to Ethereum’s “gas limit”, which is currently around 6.7 million gas on average for each block [2].
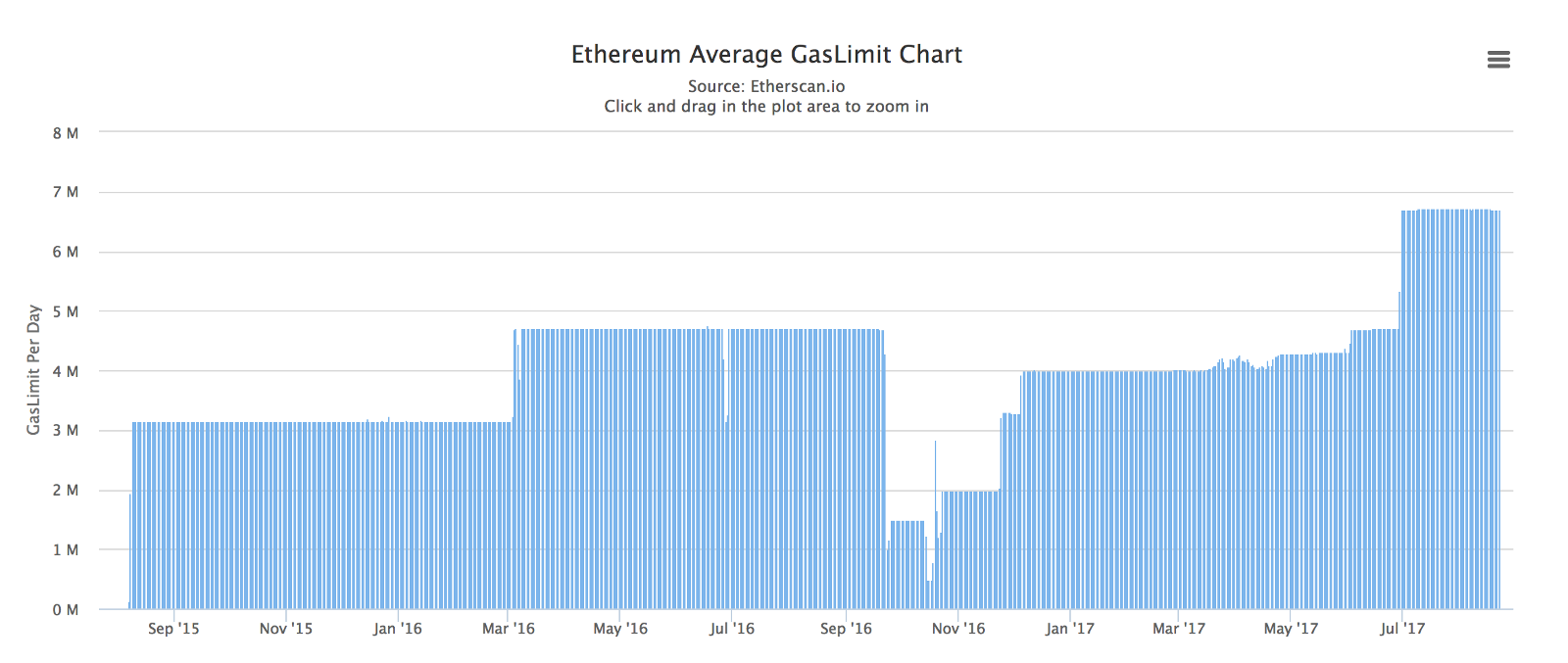
Quick “gas” primer in case the measurement is new to you: in Ethereum, gas is a measure of computational effort, and each operation is assigned a fixed amount of gas (for example, getting the balance of an account costs 400 gas, creating a contract costs 32,000 gas, sending a transaction costs 21,000 gas, etc.). Transactions have a gas limit field to specify the maximum amount of gas the sender is willing to buy. Hence, the “gas limit” for each block determines how many transactions will fit in a block based on the gas limit specified by each transaction in the block.
Ethereum’s gas limit is somewhat similar to Bitcoin’s 1 MB limit on the size of each block, with the difference being that Ethereum’s gas limit is dynamically set by miners while Bitcoin’s block size limit is hard-coded into the protocol.
This gas limit for Ethereum imposes a soft cap on the network’s computational power per block: with the current 6.7 million gas limit and the current average gas used per standard transaction of approximately 21K, we get approximately 300 standard transactions every block. The current average block time is 20 seconds which equates to roughly 15 transactions per second (300 / 20 = 15) at best [4]. This gets much lower with more complex transactions (e.g. median gas used by smart contract calls is 50K [3], which means roughly ~7 transactions per second).
Combined with the fact that the number of transactions on the Ethereum network is growing at a significant pace, you can see how this would become a problem. Daily transactions increased from approximately 40K to 240K from Q2 2016 to Q2 2017 [4], which represents a 500% year-over-year growth. Moreover, just in the past month it reached a peak of over 440K transactions per day! If we do some back of the envelope calculations, that’s an average of 5 transactions per second.
Uh oh.
Similarly, Bitcoin, despite having a theoretical limit of 4,000 transactions per second, currently has a hard cap of about 7 transactions per second for small transactions and 3 per second for more complex transactions.
Note that these limitations don’t exist for private blockchains. Private blockchains can, in fact, achieve over 1,000 transactions per second on Ethereum or Bitcoin. Why? Because if you’re running a private blockchain, you have the ability to ensure that every node on the network is a high-quality computer with high bandwidth internet connection. Scaling the blockchain currently would require us to add more compute to every node for the network to get faster. Since privately managed networks have control over every node in the network, they can do this. Moreover, since you’re on a private network, you can handle some actions that would otherwise happen on the blockchain off the blockchain, such as making sure that each node that is participating is running a real node.
I’ve been architecting and implementing a new protocol on Ethereum, and have first-handly been confronted with future-proofing the issue of scalability. Personally, I’ve been fascinated by the amount of research, discussion and most importantly, experimentation happening to solve this problem. In the rest of the post, I’ll describe some of the proposed solutions being discussed in the community to solve scalability. Each comes with unique strengths and tradeoffs.
The truth of the matter is that unfortunately, none of the solutions provide the silver bullet answer to scalability. In reality, each one of these solutions will help improve scalability incrementally. Combined together, there’s a promising outlook for the future of blockchain scalability.
Please note that the goal of this post is not to explore all the technical intricacies or to debate the merits of each proposed solution. Instead, my goal is to give you a 10,000 foot overview of some of the proposed solutions that I am aware of. If readers are interested, I can dive into some of the specific solutions in more depth in later posts. This post also assumes that you have a basic understanding of how the blockchain works. (If not, you can check out my last post “Bitcoin, Ethereum, Blockchain, Tokens, ICOs: Why should anyone care?” for a refresher.)
Let’s dig in.
Solutions
Scaling the blockchain is a known challenge and has been an active area of research for several years. Specifically, if you’ve been following the multi-year debacle in the Bitcoin community, you may have heard of two Bitcoin-specific scaling solutions known as SegWit and the 2 megabyte (MB) block size increase.
Both of these solutions aim to solve the Bitcoin-specific issue where the Bitcoin-blockchain has a built-in hard limit of 1 megabyte (MB) per block, which caps the number of transactions that can be added to a block. As a result, Bitcoin has been facing delays (sometimes hours and even days) in processing and confirming transactions for a while now. Similarly, as we saw in the previous section, Ethereum also faces limitations in its ability to scale.
Until we figure out how to scale the blockchain, we’re limited to how fast and wide the use cases can actually grow. So let’s take a look at some solutions on the table.
Proposed solution #1: SegWit (Bitcoin-only)
Every Bitcoin transaction contains:
Input
- Sender’s previous transaction details
- Sender’s unique private key (i.e. `scriptSig`) which verifies that the sender has the right amount (based on their previous transactions) to make the transaction
Output
- Amount to send
- Recipient’s public address (i.e. `ScriptPubKey`)
Out of these elements, the digital signature (`scriptSig`) is the largest in terms of size, accounting for ~60–70% of the transaction. Still, signatures are only needed at validation time.
Segregated witness (also commonly known as Segwit) is solution to separate (i.e. “segregate” ) transaction signatures (i.e. “witnesses”) from the rest of the transaction data. The signature is stripped off from within the input and moved to a structure towards the end of a transaction.
Moreover, with SegWit, the witnesses are moved to a new “witness” field in the transaction data, which allows for us to change the way block sizes are calculated. The block size limit is no longer measured in bytes. Instead, blocks and transactions are given a new metric called “weight” that correspond to the demand they place on node resources. Specifically, each byte of a segregated witness is given a weight of 1, each other byte in a block is given a weight of 4, and the maximum allowed weight of a block is 4 million, which allows a block containing SegWit transactions to hold more data than allowed by the current maximum block size. This would effectively increase the limit from 1 MB limit to a little under 4 MB, giving us a ~70% increase in transactions.
SegWit also solves other issues besides scalability, such as transaction malleability and increased security (which I won’t go into here since it’s not related to scalability.)
Proposed solution #2: 2 MB Block size (Bitcoin-only)
While one side of the Bitcoin community (the users) strongly support SegWit, the other side of the community (the miners) prefers a hard fork that would change the 1 MB block size limit to 2 MB (Keep in mind that the 1 MB limit cannot be modified without a hard fork). The basic idea is simple: by increasing the block size, it would allow for more transactions to fit in each block, allowing the network to handle more transactions per second.
Plans of this block size increase have long been a subject of heated debate in the Bitcoin community, and have gained increasing attention since the beginning of 2015, when the size of blocks started to approach the current hard limit of 1 MB.
Proposed solution #3: Off-chain state channels
State channels are essentially a mechanism by which blockchain interactions that could and would normally occur on the blockchain instead get conducted off of the blockchain. This is done in a cryptographically secure way without increasing the risk of any participant, while providing significant improvements in cost and speed. I personally believe state channels will be a critical part of scaling blockchain technologies to support higher levels of use.
A state channel works as follows:
- Part of the blockchain state is locked via multi-signature or some sort of smart contract, where the only way to update it is if a specific set of participants agree completely.
- Participants make updates amongst themselves by constructing and cryptographically signing transactions without submitting it to the blockchain. Each new update overrides previous updates.
- At some later point, participants submit the state back to the blockchain, which closes the state channel and unlocks the state again.
Steps 1 and 3 involve blockchain operations which are published to the network, pay fees and wait for confirmations. However, Step 2 does not involve the blockchain at all. It can contain an unlimited number of updates and can remain open indefinitely. In this sense, the blockchain is used purely as a settlement layer to process the final transaction of a series of interactions for the final settlement, which helps lifts the burden from the underlying blockchain.
Not only is transactional capacity increased with state channels, but they also provide two other very important benefits: increased speed and lower fees. Because a majority of the transactions are happening off-chain, payments can be handled instantaneously since updates between two parties that happen off-blockchain don’t require the extra time to be processed and verified by the network. Secondly, payments also incur lower fees because only a small number of on-chain transactions are needed to secure the settlement state channels, while a majority of the transactions are happening off-chain without fees.
There are several different implementations of this. For example, Lightning Network is a decentralized network that uses state channels via smart contracts to enable instant and scalable payments across a network of participants. Initially, Lightning Network was created for Bitcoin, but it seems now that they allow for transactions across blockchains as well.
Raiden Network is the Ethereum analogy of the Lightning network. Raiden Network also leverages off-chain state networks to extend Ethereum with scalable and instant transactions.
Proposed solution #4: Sharding
Sharding in the blockchain world is similar to database sharding in traditional software systems. With traditional databases, a shard is a horizontal partition of the data in a database, where each shard is stored on a separate database server instance. This helps spread the load across different servers.
Similarly, with blockchain sharding, the overall state of the blockchain is separated into different shards, and each part of the state would be stored by different nodes in the network.
Transactions that occur on the network are directed to different nodes depending on which shards they affect. Each shard only processes a small part of the state and does so in parallel. In order to communicate between shards, there needs to be some message-passing mechanism.
There are various ways to implement message-passing. In Ethereum’s case, the approach they are taking is a “receipt” paradigm: when a transaction within a shard executes, it can change the state of its own local shard, while also generating “receipts”, which are stored in some sort of distributed shared memory that can later be viewed (but not modified) by other shards.
Overall, sharding the blockchain requires us to create a network where every node only processes a small portion of all transactions, while still maintaining high security… A difficult challenge to say the least.
Why?
Well, for one, the blockchain protocol assumes that all nodes in the network don’t trust each other. Still, the transactions need to agree on a common state despite being processed on different computers. Since each node does not trust one other, it is not enough for a node processing transactions on shard A to simply say to the nodes processing transactions on shard B that a transaction occurred; rather, it would need to prove it to them somehow.
Additionally, since the goal of sharding is to not have every node validating every transaction, we need to figure out a mechanism that determines which nodes validate which shard in a secure way, without creating opportunities for an attacker who might have a lot of power in the system to disrupt the network.
Another reason it’s difficult to implement sharding is because a transaction executed on the blockchain can depend on any part of the previous state in the blockchain, which makes it challenging to do things in parallel. Moreover, with parallelization, you now need a fool proof way to mitigate with race conditions and the like.
There’s a lot more technical goodies to how sharding will be implemented in Ethereum — in particular, how to use “cryptoeconomic incentives” to drive actors in a system to not cheat (in this case, ensuring that nodes are passing on valid information to other nodes) — which I hope to explore in a future post.
Proposed solution #5: Plasma
Plasma was very recently introduced and is among the more promising proposed solutions to scalable computation on the blockchain.
Plasma is essentially a series of contracts that run on top of a root blockchain (i.e. the main Ethereum blockchain). The root blockchain enforces the validity of the state in the Plasma chains using something called “fraud proofs”. (Note: Fraud proofs are a mechanism by which nodes can determine if a block is invalid using mathematical proofs).
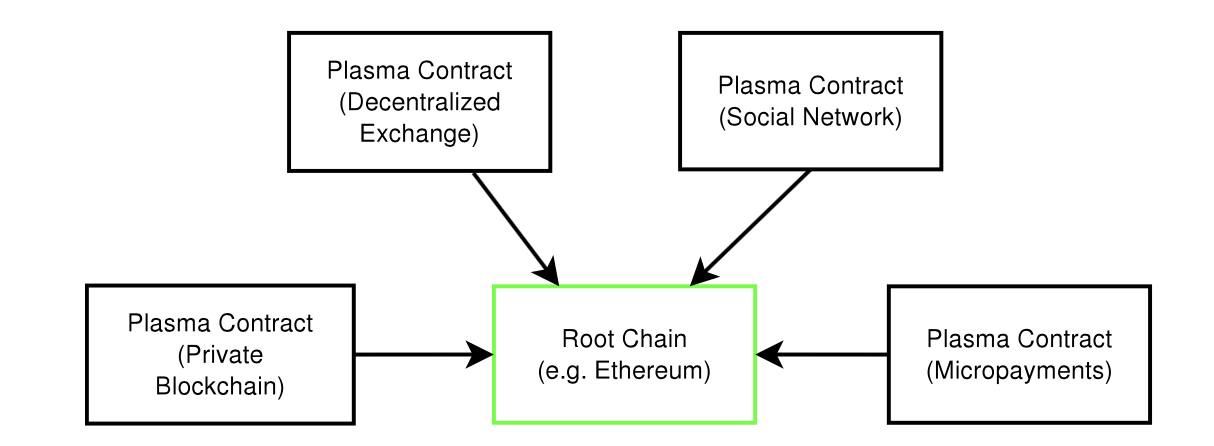
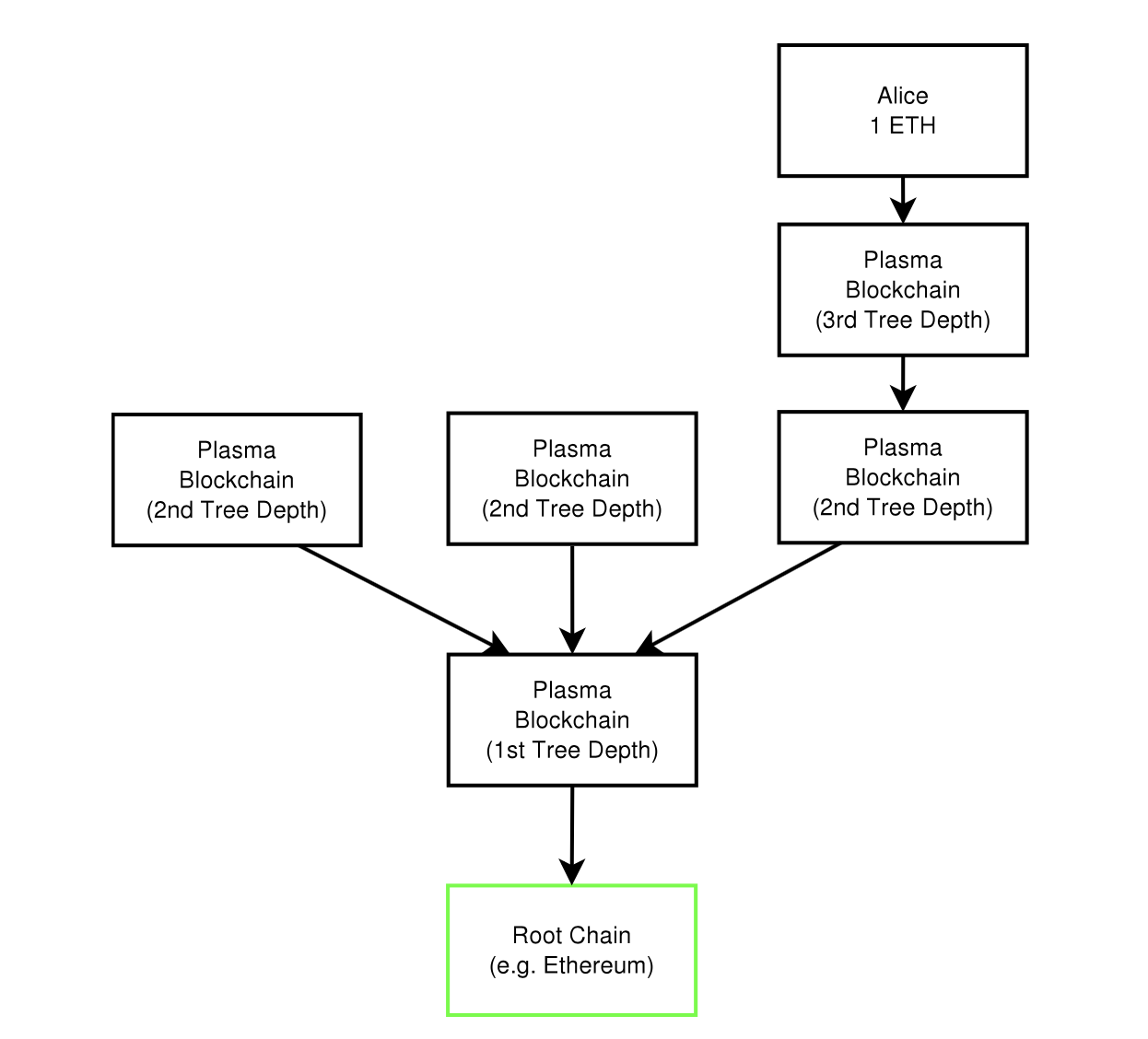
The blockchains are composed into a tree hierarchy, and each branch is treated as a blockchain that has its own blockchain history and computations that are map-reducable. We call the child chains “Plasma blockchains”, each of which are a chain within a blockchain.
The Plasma blockchain does not disclose the contents of the blockchain on the root chain (e.g. Ethereum). Instead, only the blockheader hashes are submitted on the root chain, which is enough to determine validity of the block. If there is proof of fraud submitted on the root chain, then the block is rolled back and the block creator is penalized. In other words, we only submit data to root chain in Byzantine conditions.
As a result, the root blockchain processes only a tiny amount of commitments from child blockchains, which in turn decreases the amount of data passed onto the root blockchain and allows for a much larger number of computations.
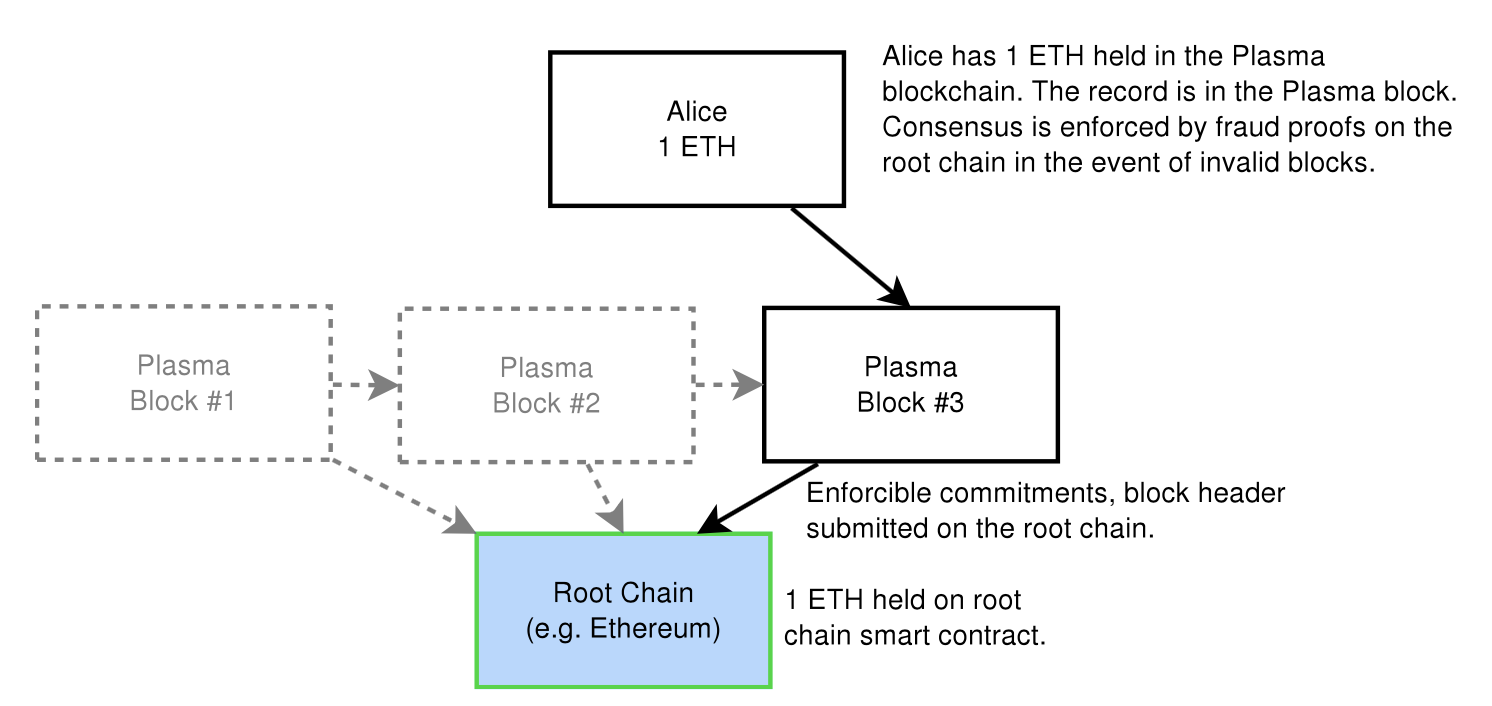
In addition, data is only propagated to those who wish to validate a particular state. This makes contract executions more scalable by eliminating the need for every node to watch every chain. Instead, they only watch the ones they are economically impacted by in order to enforce correct behavior and penalize fraud. Fraud proofs allows any party to enforce invalid blocks and ensure that all state transitions are validated.
Additionally, if there is an attack on a particular chain, participants can rapidly and cheaply do a mass-exit from the corrupt child chain.
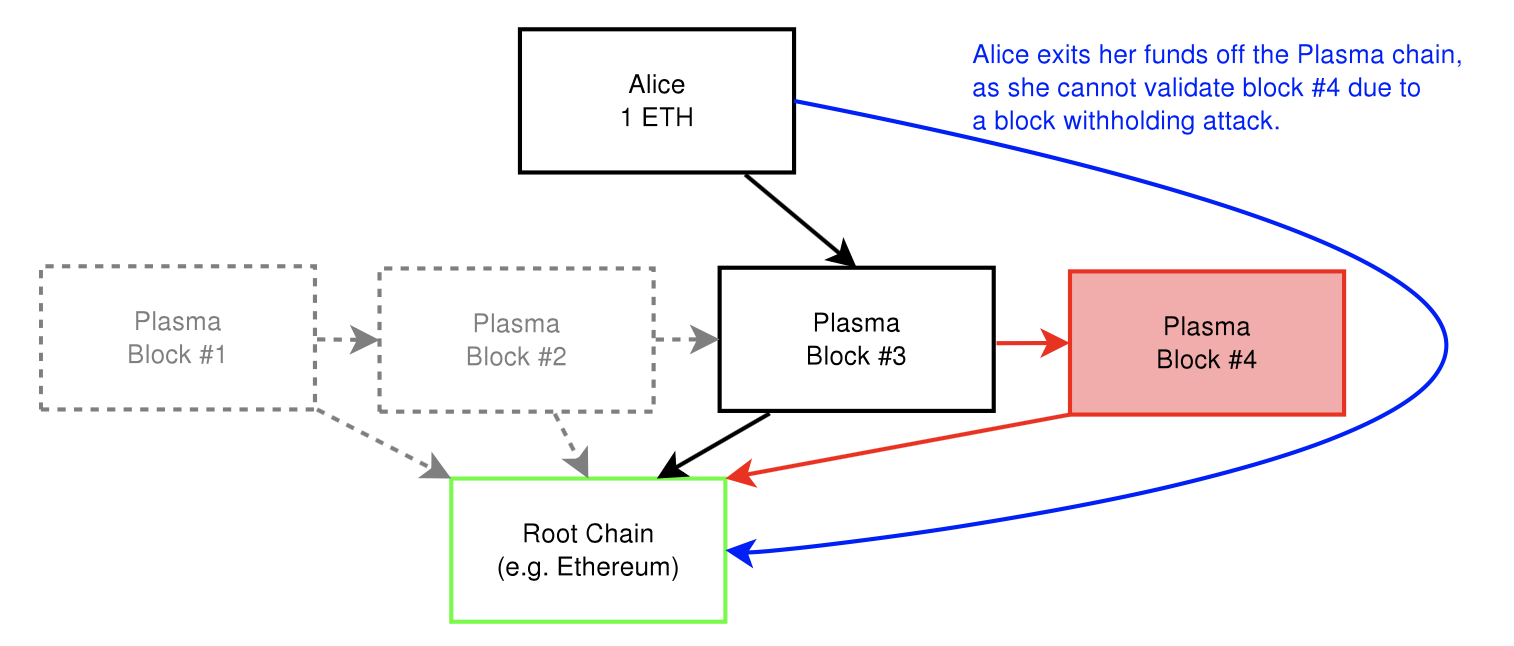
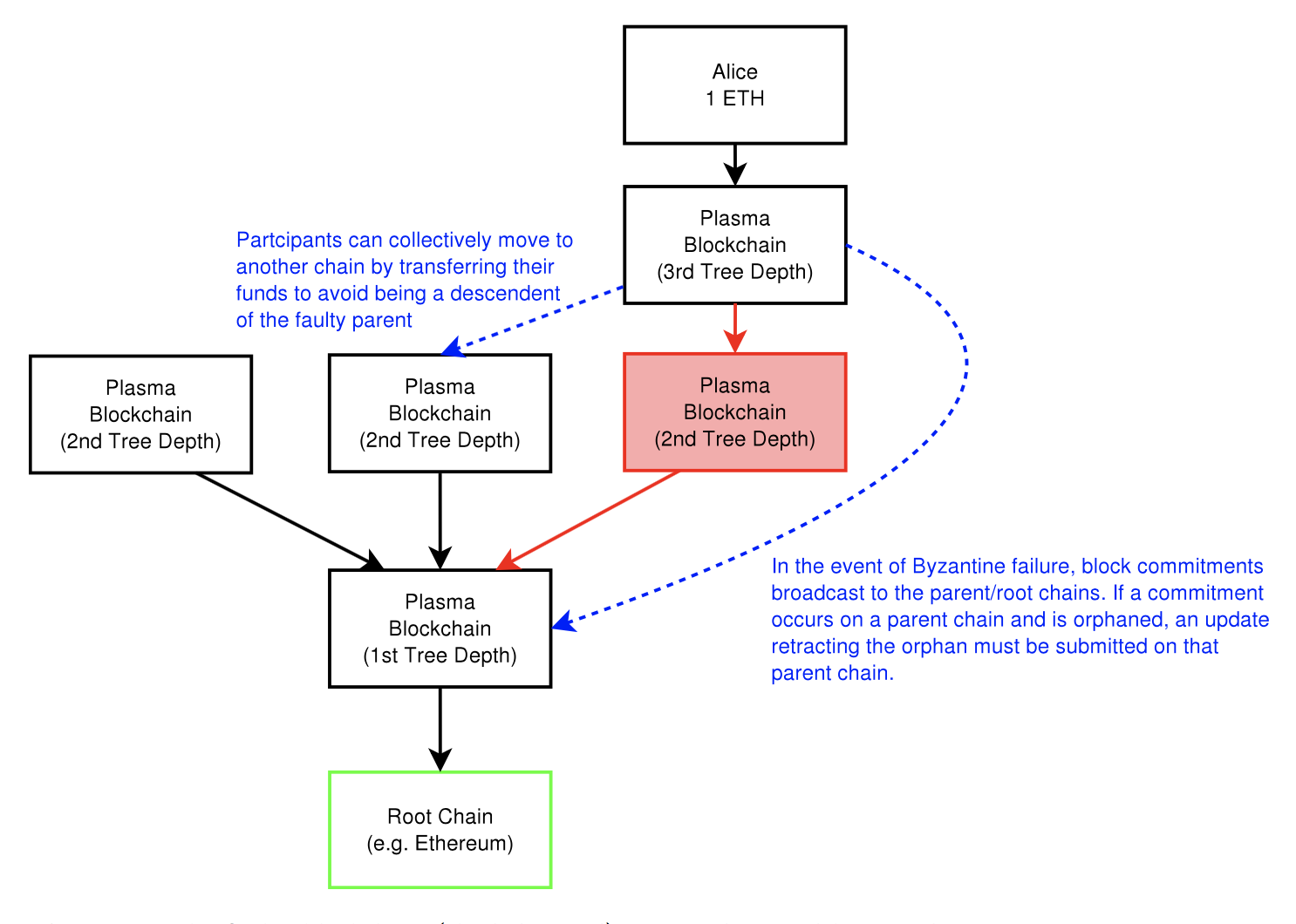
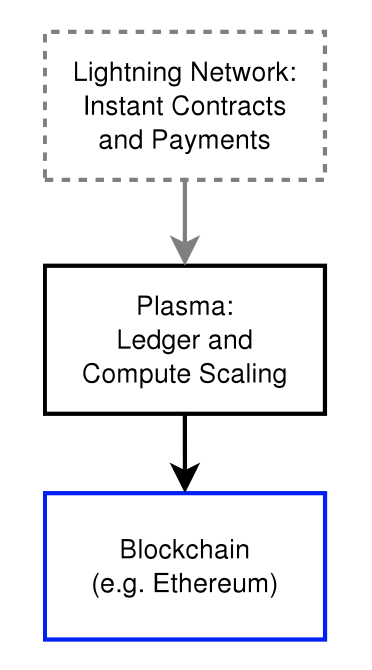
Plasma might seem similar to state channels implementations (e.g. Lightning Network) that handle transactions off chain. The main difference between state channels and Plasma is that with Plasma, not all participants need to be online to update state. Moreover, the participants do not need to submit data to the root blockchain in order to participate and confirm transactions.
The neat part about Plasma is that state channel type solutions like Lightning Network could be the main interface layer for rapid financial payments/contracts on top of Plasma, while Plasma maintains updates to the state with minimal root chain state commitments.
There’s a lot of intricate details to this solution that I hope to delve into a future post.
Proposed solution #6: Off-chain computations (e.g. TrueBit)
TrueBit is an example of a solution that uses off-chain computations to enable scalable transactions among Ethereum smart contracts. Essentially, just like state channels, TrueBit uses a layer outside the blockchain to do the heavy lifting. In other words, its a system that verifiably executes computations off-chain that would be otherwise prohibitively expensive to execute on-chain. It works like this:
Instead of every node participating, specific participants in the network, called “Solvers,” perform the computations made by smart contracts and submit a solution to the problem, along with a deposit. If the Solver is correct, then the solver is rewarded and the deposit returned. Otherwise, if the Solver cheated, the deposit is forfeited and any dispute is resolved on the blockchain using the “Verification Game”.
The Verification Games goes like this: You have a set of participants in the network called “Verifiers” who check the Solvers’ work off the blockchain. If no Verifier signals an error, then the system accepts the solution. If a Verifier does dispute the correctness of the Solver’s solution, the game proceeds in a series of rounds to settle the dispute on the blockchain, where “Judges” in the network with limited computational power adjudicate all disputes. The system is built to ensure that the work done by the Judges on the blockchain is small compared to the work required to perform the actual task off the blockchain.
At the end of this game, if the Solver was in fact cheating, it will be discovered and punished. If not, then the Challenger will pay for the resources consumed by the false alarm.
Lastly, in order to convince Verifiers that bugs actually exist and that it’s worth their effort to try to find those bugs, TrueBit does something interesting where it occasionally forces Solvers to submit incorrect solutions, which reverses the normal system incentives: the Solver gets paid for submitting an incorrect solution and penalized for submitting a correct one. This ensures there’s always a reward in the system for Verifiers who are validating transactions.
In summary, the protocol allows anyone to post a computational task, and anyone else to receive a reward for completing it, while the system’s incentive structure guarantees the correctness of returned solutions. And by moving the computations and verification process off the Ethereum blockchain into a separate protocol, it can scale to large numbers of computations without being constrained by Ethereum’s gas limit.
Other proposed solutions to blockchain scalability
There are a few other proposals floating around the crypto community that I find interesting. While the solutions are not directly aimed at solving scalability, they help indirectly address some scalability problems more easily.
Proof of stake
Similar to Proof-of-work, Proof-of-Stake is a consensus mechanism which underpins security of the blockchain by preventing doublespend.
In traditional Proof-of-Work based blockchains, miners maintain the integrity of the blockchain data by racing to solve computation-intensive, Proof-of-work mathematical puzzles in exchange for rewards. In this regard, they help validate transactions with their CPU power, and the more CPU power you have the proportionately larger your ability to influence the network is. In Proof-of-Stake, stakeholders vote with their “dollars” (in Ethereum’s case, ether) instead of compute power.
How does this work exactly?
The blockchain keeps track of certain validating nodes, called “validators”, who must place a security deposit (which is referred to as “bonding”) in order to take part in validating the blocks. If a validator produces anything that the protocol considers “invalid” in a crypto-graphically provable manner, their deposit AND the privilege of participating in the consensus process is forfeited. If they bet correctly, they earn their deposit back along with transaction fees.
Effectively, the validators make money by betting with the eventual consensus and lose money by betting against the consensus. An analogy can be made to Proof-of-work where each miner is betting with their hash power on which block will be accepted. If they bet wrong in order to cheat the system, then any block they produce will be orphaned, causing them to lose money.
There are several different kinds of Proof-of-stake consensus algorithms as well as different mechanisms for assigning rewards to validators, which I won’t go into in this post.
How does Proof-of-Stake help scalability?
One example is with sharding. Sharding with Proof-of-work is tricky to do securely. Recall that with sharding, we split up the validation responsibility among many nodes so that every node doesn’t have to process everything. However, Proof-of-work is implemented to be completely anonymous, which poses a problem because even if a single shard is secured by only a small portion of a miners hashpower, an attacker can direct all of their hashpower toward attacking this shard and disrupt the network. For example, let’s say we have two shards, A and B. A has 90% of the hashpower and B has 10%. A can attack B with only 5.1% of the total hashpower (by virtue of the majority 51% attack).
This changes with Ethereum’s current Proof-of-Stake proposal because it is designed such that validators have known identities (i.e. Ethereum addresses). Knowing their identities allows us to solve this type of targeted attack by randomly choosing a set of nodes from the entire set of validators to process any given set of transactions on a shard, which makes it impossible for an attacker to specifically target any particular shard.
Another reason Proof-of-stake helps scalability (specifically for Ethereum) is because unlike Proof-of-work which issues new tokens for miners who validate blocks, in Proof-of-Stake, validators will likely be earning only transaction fees. As a result, they have an incentive to increase the block “gas limit” (because it earns them more fee while also fitting more transactions in each block), if their validation server can handle the load. The caveat is that validators will only raise gas limit to a point that is tolerable by the other validators, because otherwise they get reduced returns from causing other, slower validators to fall out of sync.
Blockchain rent
Another Ethereum-specific solution is “Blockchain rent” [5]. Blockchain rent is a solution that aims to reduce the amount of data that is stored on the network in order to help speed up transaction times. With Ethereum, users pay for computational steps, memory, transaction logs, and permanent storage. While most of these are resources are paid for in a properly incentivized manner, the claim here is that storage is not.
In the current system, users only pay for bytes of storage. However, in reality, we can make the argument that storage is different from the other resources because it is stored forever permanently in the blocks. Instead, blockchain rent proposes to set the cost of storage to be `bytes x time`. This way, there’s an incentive built into the protocol to keep the network lighter and reduce transaction times.
Decentralized storage
Another solution for keeping the network lighter is using a decentralized storage service such as Swarm. Swarm is a peer-to-peer file sharing protocol for Ethereum that lets you store application code and data off the main blockchain in swarm nodes, which are connected to Ethereum blockchain, and later exchange this data on the blockchain .The basic premise here is that instead of nodes storing everything on the blockchain, they only store data that is more frequently requested locally and leave other data on the “cloud” via Swarm.
There’s more, but for the sake of brevity (this post is getting quite long!), I’ll leave those out for now :)
Conclusion
This topic is monstrously complex, but I hope this post was useful in giving you a big-picture idea of why scalability matters in blockchain, and how it might be solved.
This is not be a comprehensive list of by any means, and I’ll be following up on this topic as research progresses. I personally doubt that there’ll be a single silver bullet answer to scalability… but I believe some combination of approaches will eventually solve the issue and allow blockchain applications to leap forward.
As always, don’t hesitate to correct any mistakes I’ve made, or start a (healthy) discussion in the comments.
Happy blockchaining! ;)
References:
[1] http://www.r3cev.com/blog/2016/6/2/ethereum-platform-review
[2] https://etherscan.io/chart/gaslimit
[3] http://ethgasstation.info/
[4] https://etherscan.io/chart/tx
[5] https://github.com/ethereum/EIPs/issues/35