December 11, 2017.
There’s no question that blockchain technology has enormous potential.
Decentralized exchanges, prediction markets, and asset management platforms are just a few of the exciting applications being explored by blockchain developers.
Exciting enough, in fact, to raise over billions in ICOs and drive massive price rallies throughout 2017. The hype is real.
Written by Preethi Kasireddy - Originally published at this link.
Don’t get me wrong. I love the fact that blockchain “hype” is helping popularize it with mainstream users. Finally, I don’t get blank stares from people when I say “Bitcoin” or “Ethereum”.
However, there’s a flipside to this story that isn’t getting enough attention: blockchains have several major technical barriers that make them impractical for mainstream use today.
I believe that we will get there, but we need to be realistic as developers and investors. And the reality is that it could be many years before trustless systems are ready for mainstream use at scale.
Some of these technical barriers include:
- Limited scalability
- Limited privacy
- Lack of formal contract verification
- Storage constraints
- Unsustainable consensus mechanisms
- Lack of governance and standards
- Inadequate tooling
- Quantum computing threat
- … and more.
In this post, I’ll walk through these technical barriers and share examples of solutions for overcoming them.
As developers, I believe it’s critical that we shift some of our focus away from shiny new ICOs to the real technological challenges standing in our way.
NOTE: There’s no way I can cover every problem and every solution out there, but I covered the ones I’m most familiar with. Please refrain from too harshly criticizing me for not including something. I’d love for you to post anything I missed in the comments and I’ll add it if I see fit :) … And if I’ve made any mistakes or wrong assertions, please let me know!
1. Limited scalability
Currently, all public blockchain consensus protocols have a challenging limitation: every fully participating node in the network must process every transaction.
Why? Well, recall that blockchains are fundamentally “decentralized” — which means that no central party is responsible for securing and maintaining the system. Instead, every single node on the network is responsible for securing the system by processing every transaction and maintaining a copy of the entire state.
While a decentralization consensus mechanism offers us the core benefits of blockchain that we all care about — security guarantees, political neutrality, censorship resistance, etc. — it comes at the cost of scalability, since decentralization by definition limits the number of transactions the blockchain can process to the limitations of a single fully participating node in the network.
Two practical implications here:
- Low throughput: Blockchains can only process a limited number of transactions
- Slow transaction times: The time required to process a block of transactions is slow. For example, Bitcoin block times are 10 minutes, while Ethereum block times are around 14 seconds. These times are even longer during peak moments. Compare that to the nearly instantaneous confirmations you get when using services like Square or Visa.
As a result, public blockchains are forced to make a tradeoff between low transaction throughput and high degree of centralization.
In other words, as the size of the blockchain grows, the requirements for storage, bandwidth, and compute power required by fully participating nodes in the network also increase. At some point, it becomes unwieldy enough that it’s only feasible for the few nodes that can afford the resources to process blocks — leading to the risk of centralization.
At that point, we’ve made a full 360-degree turn and gotten back to a centralized system that requires trust in a few big players, whereas what we want is a system that handles thousands of transactions per second with the same levels of decentralization that cryptocurrency originally promised to offer.
Scalability Solutions
Ideally, we want a blockchain design that has similar or better security properties to Bitcoin and Ethereum, while being able to function without every single node having to process more than a certain percentage of the total transactions in the network. In other words, we need a mechanism to limit the number of nodes that need to validate each transaction, without losing the network’s trust that each transaction is valid and authentic. It might sound simple in words, but is technologically very difficult.
Scalability is a large roadblock to the future success of the platform. There are a few proposed solutions that are currently being worked on by various development teams in the ecosystem. I’ve written about this topic extensively in a previous post, which I recommend you read if you’re interested. For a brief summary of some of the current solutions, see below:
Off-chain payment channels
The idea behind a micropayment channel network is to keep most transactions off the blockchain. It’s essentially a mechanism by which blockchain interactions that would normally occur on the blockchain instead are conducted off of the blockchain. The blockchain is used purely as a settlement layer to process the final transaction of a series of interactions for the final settlement, which helps lifts the burden from the underlying blockchain.
This solves the throughput problem we discussed above because now the blockchain can scale to magnitudes of larger transaction volumes. Moreover, because a transaction happens as soon as the payment channel processes it s and not when a block gets confirmed, micropayment channels solve the transaction speed problem, eliminating the typical latency.
Some examples of micropayment channel networks in the ecosystem include Raiden Network and Lightning Network.
Sharding
The concept behind sharding is that the overall state of the blockchain is separated into different “shards,” and each part of the state is stored and processed by different nodes in the network. Each shard only processes a small part of the state and does so in parallel. Blockchain sharding is similar to sharding in the traditional database world, except with the extra hard challenge of needing to maintain security and authenticity amongst a decentralized set of nodes.
Off-chain computations
This is similar to state channels, except larger in scope. The idea is to execute computations (and not just token transfers) off-chain that would be otherwise prohibitively expensive to execute on-chain, in a way that is secure and verifiable. Moving the computations and verification process off the blockchain into a separate protocol, can achieve high transaction throughput. An example of this for Ethereum is TrueBit.
DAGs
A “DAG,” short for Directed Acyclic Graph, is a graph data structure that has vertices and edges. (A vertex is a point on the graph, and an edge is the path from one vertex to another.) DAG guarantee that there is no way to start at any vertex and follow a sequence of edges that eventually loops back to that vertex again (i.e. no loops). This allows us to have a sequence of nodes (or vertices) in topological order.
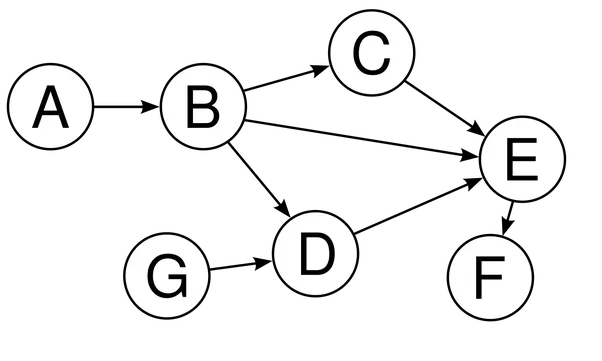
The premised behind DAG-based protocols, such as IOTA’s Tangle, for example, is to ditch the global linear blockchain altogether, and instead use DAG data structures to maintain the state of the system. To secure the network, these protocols rely on their own novel approaches that don’t require every node to process every transaction in a linear fashion.
Another DAG-based approach, SPECTRE protocol, for example, uses Direct Acyclic Graph (DAG) of blocks and mines DAG blocks in parallel to allow for more throughput and higher transaction times.
I hope to write more about DAG-based approached in future posts; the reality is that these protocols, still in very early days, have yet to be implemented and used at scale. Frankly, they have some fundamental limitations / weaknesses that have yet to be addressed to be considered viable scalable solutions.
For a more detailed overview of these scalability solutions as well as a few others, I suggest you read the post I wrote before on scalability.
2. Limited privacy
Given that blockchain transactions are not tied directly to your identity, they may appear more private. Anyone in the world can create a new wallet anonymously and transact using it.
However, it’s not quite that simple.
On one hand, it’s certainly true that the great promise of this technology is pseudonymity: transactions are recorded and stored in a public ledger, but they are linked to an account address comprised solely of numbers and letters. With no real-world identity attached to this address, the transaction’s originator seems impossible to track.
However, this appearance of total security is misleading. It’s true that a person can preserve his or her privacy as long as the pseudonym is not linked to the individual, but as soon as somebody makes the connection, the secret is revealed. One instance of such an occurrence was revealed when law enforcement agencies admitted that they were able to identify specific Bitcoin users during investigations, thus ‘deanonymizing’ them and breaking with the overall premise of a blockchain’s total transactional invisibility.
How was this accomplished?
Web trackers and cookies on merchant websites make it incredibly easy to leak information about a transaction onto the Web, where anyone, including governments, law enforcement agencies, and malicious users can readily make use of that information.
Furthermore, with a blockchain platform like Ethereum, users are interacting with smart contracts that handle more than just simple value transfers. All the details about these smart contracts are public on the Ethereum blockchain, including senders and recipients, transaction data itself, the code executed, and the state stored inside the contract.
Uploading critical business data into a blockchain where hackers, competitors, or other unauthorized parties can view the information is simply not an option for most companies. Consider:
- Electronic medical records, which are extremely private and sensitive information. It’s unacceptable to ever have that information publicly visible on public blockchains, thereby jeopardizing patient confidentiality.
- Identity verification data such as social security numbers cannot be openly stored in a public smart contract.
- Credential management such as passwords and keys have no place in an open, ultimately unsecured smart contract.
- Financial documents such as e capitalization tables or employee salaries should never be publicly associated with addresses that are easily traceable.
- The list goes on.
Privacy remains a fundamental hindrance for individuals, organizations, and industries that care about privacy and individual sovereignty. Many of us who are obsessed with blockchain and cryptocurrency have a concerted interested in enabling a trustless and censorship-resistant system that brings financial empowerment to the individual. Paradoxically, we’re using a public, easily traceable ledger to do so. (Makes my head go sideways when I think about it!)
Privacy solutions
Here are a few examples of solutions that different development teams have been working towards.
Elliptic Curve Diffie-Hellman-Merkle (ECDHM) addresses
To understand ECDHM addresses, you need to understand Diffie-Hellman Key Exchange. The idea behind a Diffie-Hellman Key Exchange is that it establishes a shared secret between two parties. This can then be used to exchange messages privately over a public network.
How?
The sender and receiver can share ECDHM addresses publicly, then use their shared secret to derive anonymous Bitcoin addresses. These Bitcoin address can only be revealed by those in possession of the secret. The only thing publicly visible is the reusable ECDHM addresses. Therefore, a user doesn’t have to worry about transactions being traced.
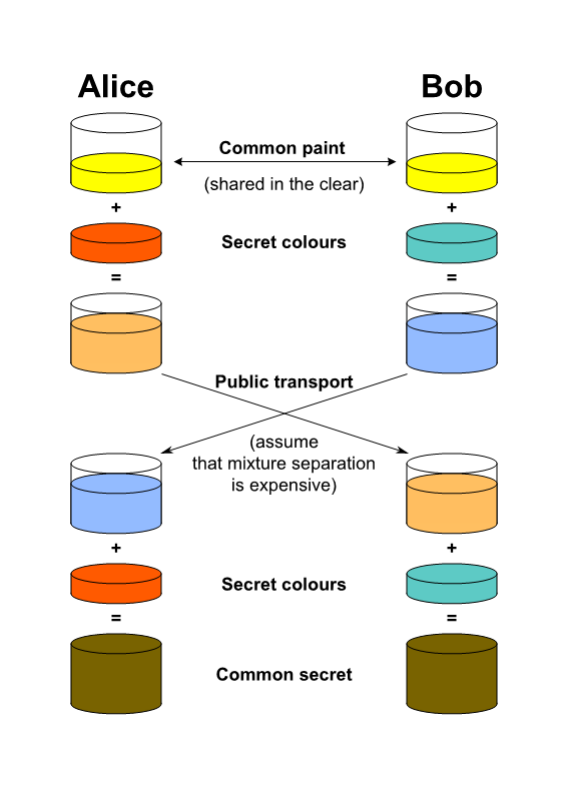
Some examples of ECDHM address schemes include Stealth Addresses by Peter Todd, BIP47 reusable payment codes by Justus Ranvier, BIP75 Out of Band Address Exchange by Justin Newton, and others. However, working implementations and actual use of these such schemes is scarce.
Mixers
The idea behind a mixer is that a group of people can combine their payments into one pool, keeping track of debts in a private ledger. Then, when funds from the pool are spent, the origins of each payment are obscured. Anyone observing the blockchain can see the amounts paid, along with the recipients, but theoretically, the person who specifically authorized the payment can’t be traced. An example of a mixing service is CoinJoin.
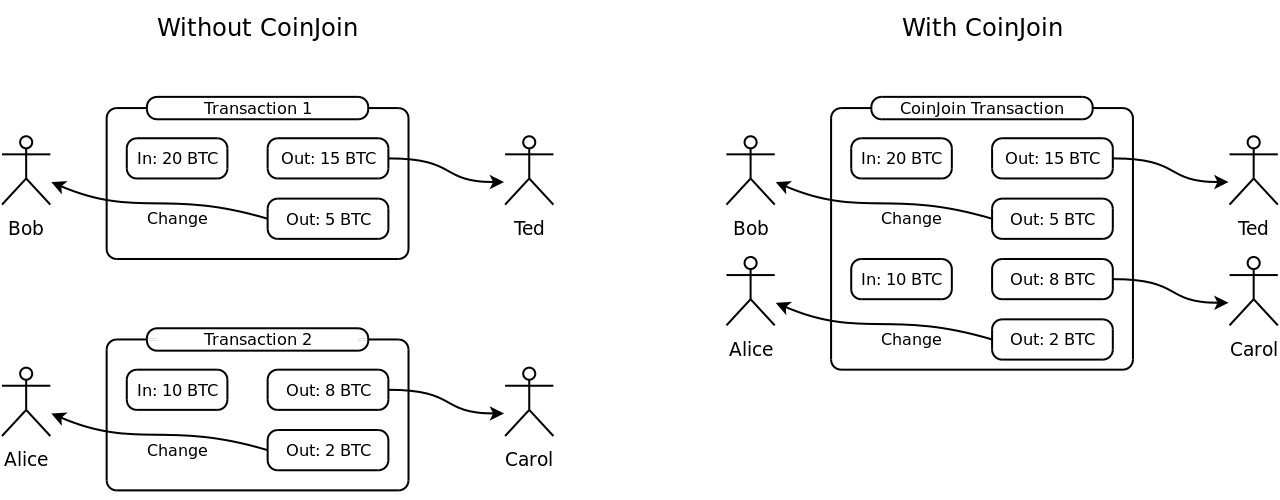
Unfortunately, mixers have proven to be an unreliable solution. For example, researchers were able to easily identify CoinJoin transactions and proved that by spending just $32,000, an attacker can unanonymize transactions with 90% success. Moreover, researchers also proved that mixers provide little protection against Sybil attacks and Denial-of-Service attacks.
Even more disconcerting is the fact that a mixer’s purportedly private ledger needs to be managed by some central entity, which means it requires a trusted third party to “mix” transactions.
Since CoinJoin is a solution that users opt into using, rather than a default methodology, very few people have historically been involved in these types of mixers’ pools, making the anonymity set too small. Therefore, it’s easy to identify whether a particular output originated from one of those few people.
Another example of a mixing solution is CoinShuffle, which is a decentralized mixing protocol developed by a group of researchers at Saarland University in Germany. CoinShuffle tried to improve upon CoinJoin by not requiring a trusted third party to assemble the mixing transactions.
Monero
Another way to tackle privacy is to create a cryptocurrency that’s private by default, such as Monero. Unlike many altcoins, Monero isn’t a fork of Bitcoin. Instead, Monero is based on an alternative protocol, CryptoNote.
The primary feature that Monero offers is an alternative “ring signature” scheme.
Ring signatures are a type of group signature, and each signer in the group has a secret and public key. Unlike traditional cryptographic signatures that prove that a transaction was “approved” by a single signer using a said private key, a group signature proves that one signer from a fixed group approved a transaction, without exposing who.
Zero-knowledge proofs
A zero-knowledge proof is when a prover convinces a verifier that they have some secret knowledge, without revealing the knowledge directly. In other words, a program can have secret inputs and the prover reveals nothing to the verifier. Zero-knowledge proofs provide fundamental primitives that can be used to build privacy-preserving mechanisms. Examples include:
Example 1: Challenge / response games
In computer security, challenge-response authentication is a family of protocols in which one party presents a question (“challenge”) and another party must provide a valid answer (“response”) to be authenticated. This “game” can be used on the blockchain to verify transaction. If a particular transaction is invalid, another node can choose to “call attention” to the invalidity. This then requires that a verifiable proof is provided, confirming that a transaction is invalid. Failing that, a “challenge” is produced that requires the originator of the transaction to produce a “response” proving e that the transaction is valid.
Let’s look at an example: Say “Bob” has sole access to some resource (e.g. his car). Alice now wants access to it as well so she can use it to go to the grocery store. Bob issues a challenge, perhaps “52w72y.” Alice must respond with the one string of characters which fits the challenge Bob issued. The only way to find the answer that is by using an algorithm known only to Bob and Alice. Moreover, Bob issues a different challenge each time. Knowing a previous correct response therefore doesn’t give Alice any advantage.
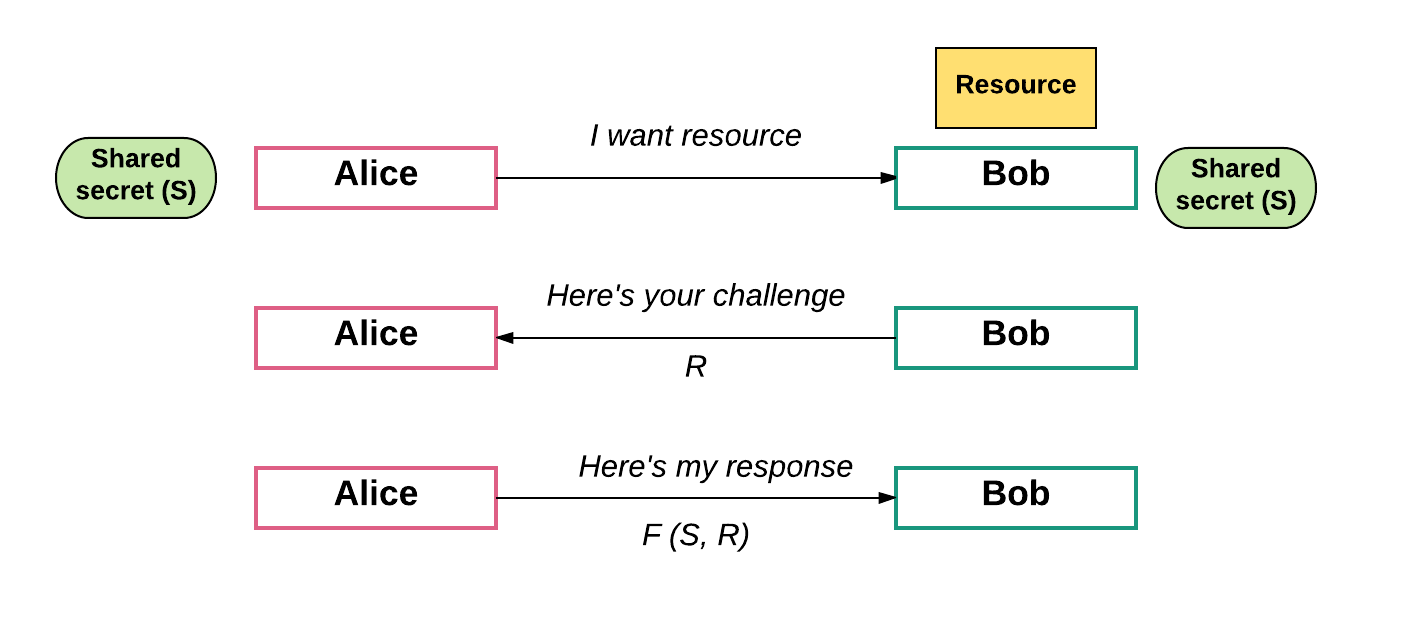
Challenge / response games are already in use in blockchains like Ethereum. However, we need libraries and tools to make these types of authentication schemes much, much easier to use.
Example 2: zkSNARKs
What exactly are zkSNARKs? Let’s break down the definition:
- zk = zero-knowledge. Doesn’t require knowledge of the information to prove that the information exists
- SNARK: Succinct Non-interactive Adaptive ARgument of Knowledge.
- “Succinct” means a succinct proof that can be verified quickly.
- “Non-interactive” means doesn’t require the verifier to interact with the prover. Instead, the prover can publish their proof in advance, and a verifier can make sure it’s correct.
- “Adaptive argument of knowledge” means a proof of knowledge of some computation.
While I hope to one day cover zkSNARKs in a post, I’ll skip the technical details here. zkSNARKs are an exciting and promising privacy-building block, with a few caveats:
- SNARKs are resource intensive.
- SNARKs allows a user to prove they have access to a secret, but the user is held responsible for maintaining the secret and having it available when needed.
- SNARKs have a setup phase during which the circuit, or computation you want to prove, is fixed. This phase needs to happen in advance among a private trusted group of people. This not only requires you to trust the people preparing the setup, but also means that SNARKs aren’t a good fit to run arbitrary computations since there’s always a preparation phase required.
Example 3: zkSNARKs + Zcash
Zcash is a privacy-preserving cryptocurrency based on zk-SNARKs. Zcash has what are called “shielded transactions,” where there is an anonymity set spanning every coin used. Shielded transactions use “shielded addresses,” which require the sender or receiver to generate a zero-knowledge proof that allows others to verify a transaction’s encrypted data without it being revealed.
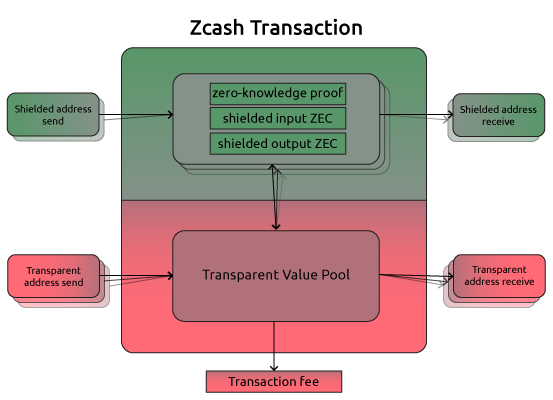
Zcash is definitely an interesting project that is worth keeping an eye on.
Example 4: zkSNARKs + Ethereum
In Ethereum’s next protocol upgrade, Metropolis, developers will have the ability to efficiently verify zk-SNARKs on-chain.
What can we do with a SNARKs-enabled Ethereum? Certain contract variables can be effectively made private. Instead of storing the secret information on-chain, it can be stored with users, who prove they’re abiding by the rules of the contract using SNARKs. Each of these users require their own trusted setup, which adds a bit of preparation overhead. But once a circuit exists, it can be used for as many transactions as needed.
What you can’t achieve with SNARKs on Ethereum, however, is autonomous privacy, separate from a user. Since SNARKs on Ethereum rely on a user to maintain the secret off-chain, without that user, there’s nowhere to keep track of the secret.
Example 5: zkSTARKs
ZK-SNARKs have a newer, shinier cousin: ZK-STARKs, with the ‘T’ standing for “transparent.” ZK-STARKs resolve one of the primary weaknesses of Zk-SNARKs: its reliance on a trusted setup. They’re also simpler because they rely purely on hashes and information theory, and are more secure against quantum computers since they don’t use elliptic curves or exponent of exponent assumptions.
Overall, despite the amazing progress we’ve made on the privacy front with some of the zero-knowledge proof based approaches mentioned above, there’s still a lot of work to do. Zero-knowledge proof libraries need to be substantially researched, battle-tested, and matured. zkSNARKs and zkSTARKs need to be experimented with on various public blockchains. Zcash needs to prove out use cases at scale in real world scenarios. We’re still a ways away from all that.
Code Obfuscation
Another privacy mechanism is code obfuscation. The goal is to find a way to obfuscate a program P such that the obfuscator can produce a second program O(P) = Q, such that P and Q return the same output if given the same input, BUT Q reveals no information about the internals of P. This allows us to keep hide private data inside of Q, such as passwords, social security numbers, etc., but still make use of it within programs.
While researchers claim that total black box obfuscation is impossible, there is a weaker notion of obfuscation, known as indistinguishability obfuscation, that researchers say is possible. The definition of an indistinguishability obfuscator O is that if you take two equivalent programs A and B (i.e. same inputs to either A or B produce the same outputs) and calculate O(A) = P and O(B) = Q, then there is no computationally feasible way for someone who doesn’t have access to A or B to tell whether P came from A or B.
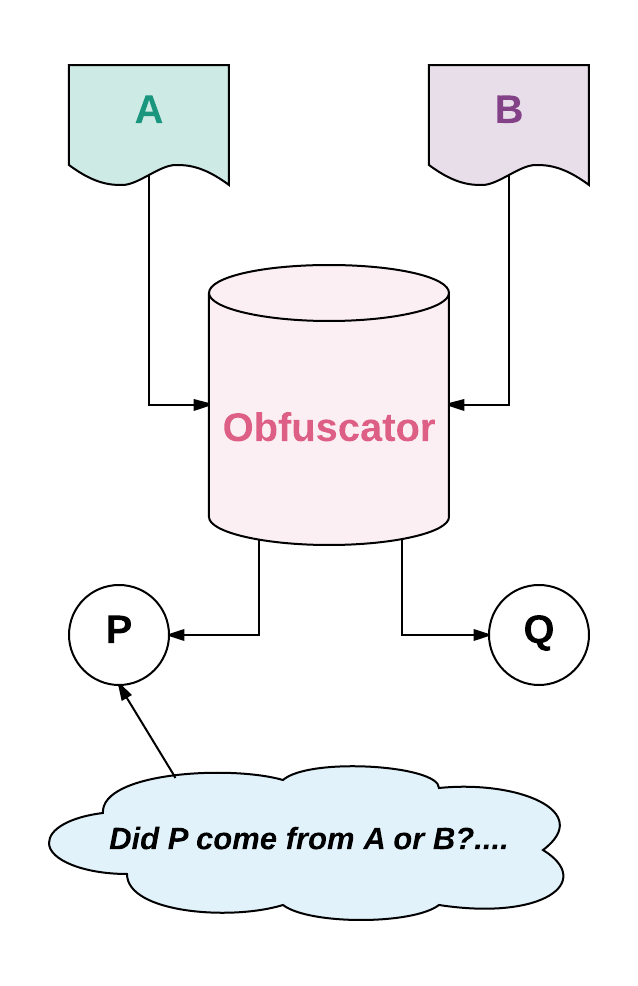
Source: https://en.wikipedia.org/wiki/CoinJoin
In the blockchain space, an oracle is a party which relays information between smart contracts and external data sources. It essentially acts as a data carrier between smart contracts on the blockchain and external data sources off the blockchain. So one approach to keeping information “private” is simply to use oracles to fetch private information from an external data source.
Recently, researchers Craig Gentry, Amit Sahai, et al. were able to accomplish indistinguishable code obfuscation. However, the algorithm comes with high computational overhead.
If this construction can be improved upon, the potential benefits are massive. The most interesting possibility in the world of cryptocurrency is the idea of an on-blockchain contract containing private information.
For example, we can imagine an Ethereum contract which contains a user’s password to Coinbase. Then we can write a program such that if certain conditions of the contract are satisfied, the contract will initiate an HTTPS session with Coinbase using some intermediary node, log in with the user’s password, and make a trade. Because the information in the contract will be obfuscated, there will be no way for the intermediary node, or any other player in the blockchain, to modify the request in-transit or determine the user’s password.
Oracles
In the blockchain space, an oracle is a party which relays information between smart contracts and external data sources. It essentially acts as a data carrier between smart contracts on the blockchain and external data sources off the blockchain. So one approach to keeping information “private” is simply to use oracles to fetch private information from an external data source.
Trusted Execution Environments
Trusted Execution Environment (TEE) is a secure area of the main processor. It guarantees code and data loaded inside is protected with respect to confidentiality and integrity. This trusted environment runs in parallel with the user-facing operating system, but is intended to be more private and secure than the user-facing OS.
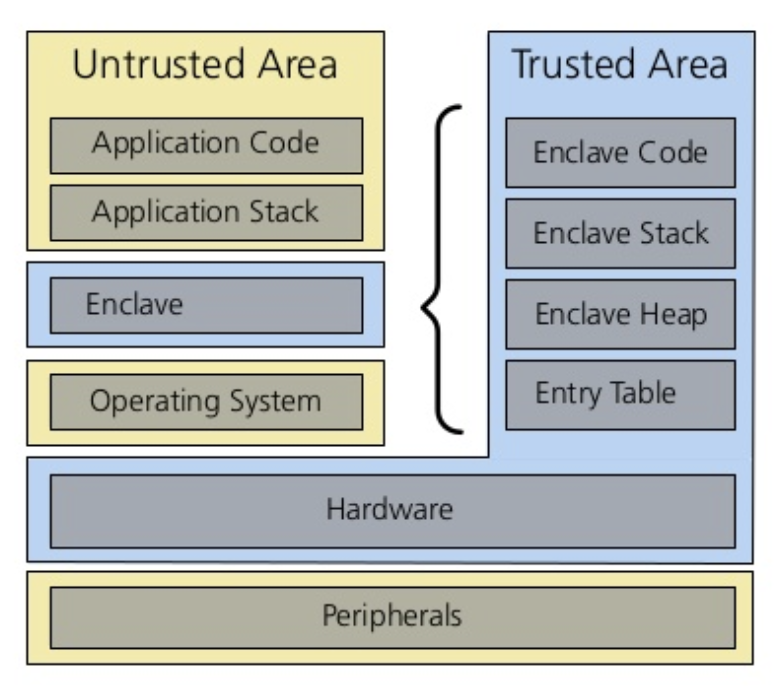
There’s early research and development going on into TEEs to determine how they can be used to enable privacy on the blockchain. I’m personally very excited for more security experts to tackle these solutions. We definitely need more experts looking into this.
3. Lack of formal contract verification
Formal verification of smart contracts remains a HUGE unsolved problem. First, let’s understand what it even means to “formally verify” a contract by understanding what a “formal proof” is. A “formal proof” in mathematics means a mathematical proof that has been checked by a computer using the foundational axioms of mathematics and primitive inference rules.
More broadly, formal verification in relation to a software program is a methodology to determine whether the program behaves according to a specification. In general, this is done with a concrete specification language used to describe how the inputs and outputs of functions should relate. In other words, we first state an invariant about the program, and then we are obliged to prove that statement.
One example of a specification language is Isabelle, which is a generic proof assistant that allows mathematical formulas to be expressed in a formal language and provides tools for proving those formulas in a logical calculus. Another specification language is Coq, which is a formal language to write mathematical definitions, executable algorithms, and theorems.
So why is it important to do formal verification for programs encoded within smart contracts?
For one, smart contracts are immutable, meaning you can’t update or fix them once they’ve been deployed onto the main Ethereum network. So that means we need to get everything right to the tee before we can deploy and use those contracts in real-world applications. Moreover, smart contracts are publicly accessible and anything stored within smart contracts is open for anyone to view; anyone can also call into the public methods of smart contracts. While this provides openness and transparency, it also makes smart contracts very attractive targets for hackers.
The reality is that writing trustworthy smart contracts that are bug-free is difficult, regardless of how much precaution you take. Moreover, with Ethereum, for example, verifying EVM code is incredibly difficult because of the way the EVM instructions are designed. This makes building formal verification solutions for Ethereum even more difficult. Regardless, formal verification is a strong approach to reducing the risk of bugs and attacks. They provide a higher guarantee of correctness than traditional approaches (e.g. testing, peer reviews, etc.) and we desperately need better solutions.
Formal verification solutions
I wish I had more publicly available solutions to show off in this section, but unfortunately there aren’t many. One very early set of examples I found was done by Yoichi Hirai, who is a formal verification engineer for the Ethereum foundation. He was able to produce early results for verifying several smart contracts, including a small “deed” contract. Although very small, this is the first “real” contract that I’ve seen analyzed in a theorem proving environment.
As Yoichi himself says…
“The verification result is far from perfect. I am still finding more problems in the verification setup than in the verified contracts. The EVM (Ethereum Virtual Machine) implementation is not tested against others! I am making this public already because this project makes a good example on the amount of work (and the level of detail) required to verify a smart contract using the machine-assisted logical inference. At this point already, if I were to implement a smart contract that holds more than 100k dollars, and if I am in charge of the schedule, I would consider this kind of development (the other option is to try the contract with smaller values first).”
There are other teams like Tezos which are completely forgoing using Solidity as the language and the EVM as the VM, and instead are building their own smart contract programming language and VM that facilitate formal verification.
Whatever the right approach, whether it be overhauling the EVM to make it easier to formally verify or building a whole new language that is inherently easier to verify, we need more work put into this effort. We need more researchers and developers working on formal verification. We need formal verification libraries and standards in every possible programming language.
4. Storage constraints
Most applications that get built on a public blockchain will require some sort of storage solution. (User identities, financial information, etc.).
However, storing information on a public blockchain database means that the data is:
- Stored by every full node in the network.
- Stored indefinitely since the blockchain database is append only and immutable.
Therefore, data storage imposes a huge cost on a decentralized network where every full node has to store more and more data into infinity. As a result, storage remains a huge hurdle for any realistic application that gets built on the blockchain.
Storage Solutions
There are several early projects that are using various strategies for splitting up the data into shards and storing it in a distributed fashion across participating nodes (i.e. distributed storage). The basic premise here is that instead of every node storing everything, there are a set of nodes that split or “distribute” the data among themselves. A few example of projects include:
- Swarm: Swarm is a peer-to-peer file sharing protocol for Ethereum that lets you store application code and data off the main blockchain in swarm nodes which are connected to Ethereum blockchain. You can later exchange this data on the blockchain.
- Storj: A solution where files and data are first sharded, encrypted and then distributed to multiple nodes such that each node only stores a small portion of the data: hence, “distributed storage.” Then the Storj Coin (SCJX) is used to pay for storage and acts as an incentive for nodes that store a portion of the user’s files or data.
- IPFS: An alternative p2p hypermedia protocol that provides a high throughput, content-addressed block storage model, with content-addressed hyperlinks. Essentially, it allows files to be stored in a permanent and decentralized fashion, while providing historic versioning for files and removing duplicates.
- Decent: Decent is a decentralized content sharing platform which allows users to upload and monetize/share their work (videos, music, ebooks, etc.) without relying on a centralized third party. Users can access content in a more affordable way by skipping these intermediaries while the nodes that host the content are rewarded with fees.
- … and more.
5. Unsustainable consensus mechanisms
Blockchains are “trustless”. Users don’t have to trust anyone else with their transactions. Not needing to trust anyone else affords users attractive properties such as autonomy, censorship resistance, authenticity, and permissionless innovation.
The mechanism used over time to enable a trustless blockchain, not easily subverted by attackers, is called a “consensus protocol.” Consensus protocols are not new to Bitcoin and other blockchains. For example, in 1992, Dwork and Naor created one of the first “proof-of-work” systems where one could generate cryptographic proof of computational expenditure to get access to a resource, without having to rely on trust. This system was used to combat junk mail. Adam Back later created a similar system called Hashcash in 1997. Then in 2003, Vishnumurthy et al. used proof-of-work to secure a currency for the first time, except in this case, the token was used not as a general currency but to maintain a peer-to-peer file trading system.
Five years later, Nakamoto came out with proof-of-work as a mechanism to secure a value token, Bitcoin. This underlying consensus mechanism allowed Bitcoin to become the first widely adopted global decentralized transaction ledger.
Proof-of-work consensus
Proof-of-work is a scheme that consists of solving problems that are difficult to solve, but easy to verify. Miners carry out computationally expensive calculations using their compute power, and the Bitcoin system rewards miners that present such solutions with new Bitcoins and transaction fees. The more compute power a miner has, the more “weight” they have on deciding on the consensus.
Proof-of-work consensus allowed Bitcoin to become the first truly widely adopted form of decentralized digital currency. It solved the “double-spend problem” without requiring any trust third party. However, proof-of-work isn’t perfect, and there’s still a great deal of research and development required to build a more viable consensus mechanism.
What are the issues with proof-of-work?
1. Specialized hardware has an advantage
One downside of proof-of-work is the use of specialized hardware. In 2013, devices called “application-specific integrated circuits” (ASICs) were designed solely for the purpose of mining Bitcoin, providing a 10–50x rise in efficiency. Ever since, mining with a regular computer’s CPU and GPU has become completely unprofitable, and the only way to mine is with ASICs that you manufacture yourself or buy from an ASIC manufacturer. This is far from the “decentralized” nature of the blockchain, where everyone has the opportunity to contribute to the security of the network.
In order to mitigate this issue, Ethereum has chosen to make its PoW algorithm (Ethhash) sequentially memory-hard. This means that the algorithm is engineered so that calculating the nonce requires a lot of memory AND bandwidth. The large memory requirements and high bandwidth requirements make it difficult for even a super-fast computer to discover multiple nonces simultaneously. This reduces the risk of centralization and creates a more level playing field for the nodes that are doing the verification.
Of course, that’s not to say that there won’t ever been an ASIC for Ethereum in the future. Specialized hardware remains a huge risk for PoW algorithms.
2. Mining pool centralization
The concept behind a mining pool is that instead of each user mining on their own and having a tiny chance of earning the block reward, they mine for a pool.. The pool then sends them a proportionate, consistent payout. The problem with mining pools is that since they have more “weight” in the network, large mining pools have less variance in their returns than a single user. Over time, a few pools start to control the majority of the network and the concentrated set of pools continue to gain more power over time. Right now, for example, the top five mining pools own close to 70% of the total hashrate. Scary, to say the least.
3. Energy waste
Miners spend massive amounts of compute power to run the computations that solve the proof-of-work algorithm, but unfortunately, all of this computational work has no value to society. According to Digiconomist’s Bitcoin Energy Consumption Index, Bitcoin’s current estimated annual electricity consumption stands at 29.05TWh, which represents 0.13% of total global electricity consumption. To give you context on how much that really is, Bitcoin mining is now using (read: wasting) more electricity than 159 individual countries.
As public blockchains like Bitcoin that use proof-of-work consensus continue to scale, increasingly, more energy will be wasted. If the goal is for the public blockchain to scale to millions of users and transactions,the unsustainable wasted energy and computation costs of proof-of-work are not conducive to this outcome.
Consensus Solutions
Useful proof-of-work
One way of solving the energy waste problem is to make the proof-of-work function solve something which is simultaneously useful. For example, imagine a scenario where miners are spending their compute power to solve difficult AI algorithms, instead of solving a random SHA256 problem required by proof-of-work.
Proof-of-stake
One approach to solving the mining centralization problem is to abolish mining entirely and move to some other mechanism for counting the weight of each node in the consensus. That is what proof-of-stake aims to do.
Instead of miners putting in compute power, they put in a “stake” (i.e. money). As Vitalik notes, instead of “one unit of CPU power, one vote” it becomes “one currency unit, one vote.”
Proof-of-stake eliminates the need for hardware and is therefore immune to the hardware centralization concerns discussed above. Moreover, since miners aren’t required to expend massive amounts of energy to compute solutions to proof-of-work algorithms, proof-of-stake is inherently more energy efficient.
However, as with any technology, there’s no free lunch. Proof-of-stake algorithms have their own fundamental challenges. More specifically, these include:
- Nothing-at-Stake problem: With proof-of-stake, when there is a fork in the chain, whether the fork is accidental or malicious, the best strategy for any node that is validating a transaction is to “mine” on every chain. They can do this since they aren’t expending physical computational effort and are only voting with their dollars. This means the miners in proof-of-stake will be rewarded regardless of which chain wins (i.e. “nothing is at stake” to prevent them from mining on every chain).
- Long-range attacks: When there is a fork in proof-of-work chains, a miner will start a fork a few blocks behind the current head of the main chain. The further back a miner gets in the chain, the more difficult it becomes to catch up to the main chain since it requires the compute power of over half the network to do so. However, with proof-of-stake, a participant can start a fork thousands or millions of blocks back, since the only thing required is stake, or money. This means a participant can try to obtain the keys of past participants and then generate millions of blocks onto a new chain, making it difficult for users to know which blockchain is the “correct” one.
- Cartel formation: In a decentralized system that is governed by economic incentives, a very real risk is the formation of coordinated efforts and oligopolies. As Vlad Zamfir, an Ethereum researcher, notes, “Cryptocurrency is incredibly concentrated. So is mining power. Oligopolistic competition is the norm in many ‘real-life’ markets. Coordination between a small number of relatively wealthy validators is much easier than coordination between a large number of relatively poor validators. Cartel formation is completely expected, in our context.”
In order to viably replace proof-of-work with a new consensus mechanism like proof-of-stake, we need an algorithm that solves the nothing-at-stake problem and long-range attack problems, without introducing new collusion risks.
A good amount of progress in resolving this problem has been made by teams like Tendermint and Ethereum. Tendermint was one of the first to adapt traditional BFT research to blockchains by building a viable proof-of-stake consensus engine for blockchains. However, Tendermint has its own downsides (a topic for another post). Similarly, Ethereum has made great progress with their implementations of proof-of-stake, but the reality is that there’s nothing running on a live network at scale today.
Unlike proof-of-work, proof-of-stake is unproven and far less understood. Understanding the different trade-offs of various designs requires further research and experimentation. As such, there’s a strong need to collaborate in creating a more efficient, fast, and secure consensus systems based on these early works.
6. Lack of governance and standards
It goes by without saying that a public, decentralized blockchain has no central authority or organization making decisions. While on one hand, this affords us the dream we all are after — a completely trustless, open, and permissionless system — on the other hand, there literally is no safe upgrade path for the protocol, and no one responsible for setting and maintaining standards.
While we definitely want to keep the development of blockchain technology as decentralized as possible, we still need some organization amongst developers and others in the ecosystem to agree on new standards, features and upgrades. It’s unclear how you achieve this without leading to at least some centralization (e.g. The Ethereum Foundation).
The current status quo in Ethereum, for example, is that there are typically one or two developers who are leading the effort on specific standards or features. While this works for now, this model has flaws. For one, it’s not efficient — if the developer(s) leading the effort get busy, or forget to respond for a few days, or weeks, the progress on the standard just stalls, regardless of how important the standard is for everyone building on the public blockchain. Defining a standard without clear leadership is chaos and makes it impossible to quickly reach a consensus on timely issues, especially as the community gets bigger.
Another approach is to leave it completely open and decentralized. However, this has shown to be ineffective, leading to multi-year debacles.
There needs to be a better way.
Tezos is one example of a public blockchain that aims to create the ability to upgrade the protocol from within the protocol using on-chain governance, although it’s still very much an idea and not live or proven out.
Overall, Blockchain governance is an incredibly tricky problem and finding a balance between centralized and distributed control will be key to keeping development on the right path.
7. Inadequate tooling
Adequate tooling is essential to developers’ jobs, especially if said developers want do their work effectively and efficiently. Terrible tooling breeds horror stories.
It goes without saying that the developer tooling currently available for the blockchain ecosystem is unacceptable. Developing a functional protocol or decentralized application on the blockchain is a daunting task even for today’s most seasoned developers.
As a Solidity and blockchain developer, here’s what I’ve personally found missing from the tooling ecosystem:
- An IDE that has good linters and all the necessary plug-ins for effective smart contract development and blockchain analysis.
- A build tool and compiler that is well-documented and easy to use.
- A deployment tool that doesn’t suck.
- Technical documentation that actually exists or is not completely out of date for various APIs and frameworks.
- Testing frameworks that aren’t lackluster. There are a few tools for Ethereum like Truffle which are passable, but more options and experimentation around testing frameworks are badly needed. I’ve seen too many smart contracts go completely untested out in the wild while moving millions of dollars. A lack of testing is not acceptable under any circumstances, but particularly not when such vast amounts of money are involved. For example, the BAT token sale smart contracts have no test suite, yet those contracts were used to collect $36 million in 24 seconds. Any rational human knows that if a contract can move that much money around, it is subject to attack.
- Debugging tools. Oh boy. Debugging Solidity code is like searching for gold in a dark tunnel with a blindfold on. In my previous line of work, I was in web development, and being able to step through code line by line using a debugger was truly a lifesaver. Not having such a tool, or even one that comes remotely close, is incredibly frustrating and unproductive when developing in Solidity. We desperately need tools that make it easier to isolate and diagnose problems.
- Logging tools. Same as above.
- Security auditing. This is a big one. There’s just one notable security auditing service for Ethereum that I’ve heard of, Open Zepplin. While they are doing great work for the ecosystem with their auditing service, an industry that’s raising billions of dollars using smart contracts needs more than one lone startup. Companies and engineers need to create more advanced tools and services, and more security experts are necessary to help thoroughly audit smart contracts. The only time there’s any noticeable attention paid to smart contract security is after the fact, when attacks such as the two Parity hacks or the DAO hack occur. Then, of course, the blame is placed on the developers who wrote the smart contracts, or even worse, on the core Ethereum team. I think that’s unfair. Developers shouldn’t be responsible for knowing how to do security audits for their own code. That’s like asking Stephen Curry to do his own accounting. It doesn’t work that way. We desperately need the help and expertise of security engineers and researchers. We need investors to put their mouths where their monies are and fund efforts aimed at making smart contracts and blockchains more secure.
- Block explorers and analytics. For Ethereum, we have a block explorer called Etherscan. For Bitcoin, we have explorers like Blockchain.info, Blockexplorer, or Blockcypher. These all are great community efforts. In fact, I use Etherscan extensively. But to do any kind of serious chain analytics, it’s nowhere near enough. There’s all sorts of interesting data we could and should be analyzing about public blockchains.
8. Quantum computing threat
One of the looming threats to cryptocurrency and cryptography is the issue of quantum computers.
Although quantum computers today are still somewhat limited in what types of problems they can solve, it won’t always be that way. The scary truth is that most popular public-key algorithms can be efficiently broken by a sufficiently large quantum computer.
It’s important that as we design and build the blockchain and the cryptography that underlies it, we need to be thinking about how to make these properties quantum-proof.
Quantum-proof solutions
While I am by no means an expert on this, my very limited understanding is that post-quantum cryptography research is currently focused on six different approaches: Lattice-based cryptography, Multivariate cryptography, Hash-based cryptography, Code-based cryptography, Supersingular elliptic curve isogeny cryptography, and Symmetric key quantum resistance systems like AES and SNOW 3G.
Regardless of the final solution, building cryptographic solutions that are quantum-proof is something that should be top of mind.
Miscellaneous challenges to keep in mind
- We need more robust solutions that are capable of inter-blockchain communication to allow multiple chains (e.g. Bitcoin, Ethereum, Litecoin, etc.) to communicate and transact with one another seamlessly.
- We need better key management systems built into the blockchain tooling, for the sake of applications built on top.
- We need more efficient signature schemes and other cryptographic systems that low-resource devices can handle without sacrificing security.
- … and more.
Conclusion
It’s unfortunate that so much of the mindshare and funding around blockchain is being pushed into ICOs. Meanwhile, a few researchers and developers are desperate to solve these problems but are starved of adequate resources.
Unfortunately, many are financially incentivized to ignore the problems — including some of the most influential developers and leaders in the space.
My goal for the coming year is to continue to:
- Increase awareness around these issues
- Pour as much of my time to contribute towards these solutions
- Help empower other researchers and developers to do the same
Regardless of whether or not the current investment climate turns out to be a bubble or not, I’m a firm believer in that the blockchain is here to stay. We just need to put in some elbow grease as developers to knock out the barriers holding it back from mainstream use. And we need investors to seek and fund these efforts.